Productionizing dbt as a Cloud Run Job: Infrastructure Management with Terraform and CI/CD with GitHub Actions - Part 1

In this multi-part series let us try to get a dbt job running as a Cloud Run job with the infrastructure managed by Terraform and CI/CD with GitHub Actions
Part 1: Setup to run the dbt job locally Part 2: Setup terraform for the infrastructure needed Part 3: Add GitHub Actions which enables the creation of the docker image in the Artifact registry and also to deploy the infrastructure
What is dbt
dbt (Data Build Tool) is an open-source tool that simplifies data transformation by writing SQL statements combined with Jinja. This gives the flexibility to add ‘if-else’, ‘for’, and ‘while’ statements while writing SQL queries.
Install dbt locally
Create a virtual environment and activate it. My preferred way is to use pyenv to manage the virtual environments. Once you activate the virtual environment, install the dbt-bigquery library using pip.
1
pip install dbt-bigquery
Create dbt project
After installing the dbt library, set your working directory to a location in which you would like to create your new dbt project. Running the below command would get you started with dbt core.
1
dbt init
It would prompt you to enter a name for your project. We enter “jaffle_shop” and proceed.

If we have multiple dbt libraries installed, we might see more than this. In our case, we choose ‘bigquery’ as the database to use. 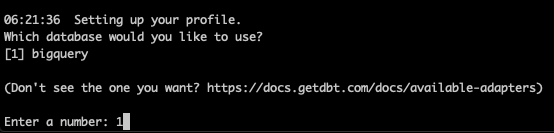
After that, we could choose the authentication method needed. We choose ‘oauth’ for this and proceed further. Then choose the location needed and hit enter. 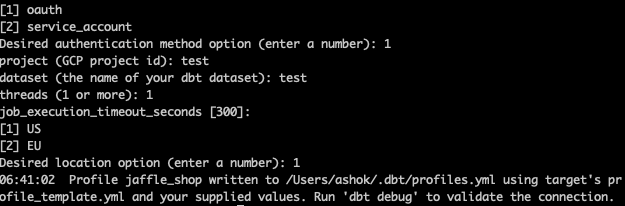
Now dbt would have created a profiles.yml file which would be in the location /Users/<USERNAME>/.dbt/ by default. Let us move it to a location inside our jaffle_shop dbt project folder.
1
cp /Users/<USERNAME>/.dbt/profiles.yml jaffle_shop
Let us explore the contents of the profiles.yaml file. We will make the below changes for the fields dataset, location and project to read from the environment variables. We would pass the value for these environment variables from the Cloud Run Job which in turn would be picked up from the Terraform code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
jaffle_shop:
outputs:
dev:
dataset: ""
job_execution_timeout_seconds: 300
job_retries: 1
location: ""
method: oauth
priority: interactive
project: ""
threads: 1
type: bigquery
target: dev
Now let us create the models needed for our project. We will pick the dbt-tutorial project and use the sample datasets jaffle_shop and stripe.

We would use the sample jaffle shop GitHub repository and create our models.
Our models would look like in the below structure.
1
2
3
4
5
6
7
8
9
.
├── marts
│ ├── customers.sql
│ └── orders.sql
├── sources.yml
└── staging
├── stg_customers.sql
├── stg_orders.sql
└── stg_payments.sql
Let us explore the lineage of the customers model. 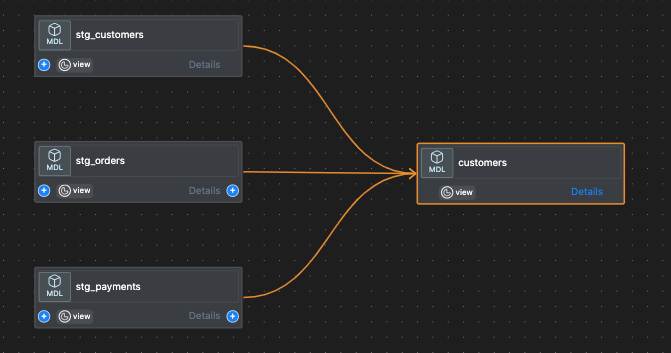
Now let us explore the lineage of the orders model. 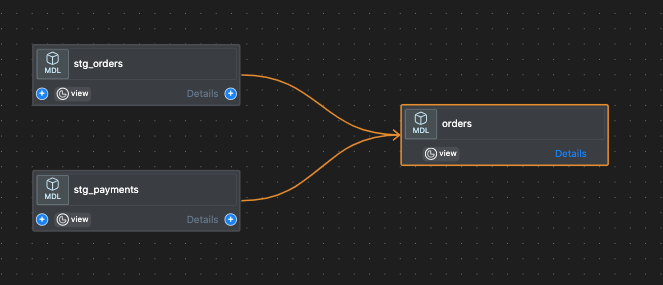
Remember that our dbt model needs a few environmental variables to run. We will create .env file and maintain the values for it.
1
2
3
4
DBT_TARGET=dev
PROJECT_ID=<>
REGION=<>
DATASET=<>
Now running the below command would export all the rows from the env file as an environmental variable.
1
export $(xargs <.env)
We are all set to run our first dbt model. Running the below command would start the dbt job. dbt would look through all the SQL files and run them in sequence.
1
dbt run --project-dir jaffle_shop/dbt --profiles-dir jaffle_shop/dbt --target ${DBT_TARGET}
We could see that dbt found 5 models in our project and successfully created them.
1
2
3
4
5
13:55:18 Finished running 5 view models in 0 hours 0 minutes and 11.60 seconds (11.60s).
13:55:18
13:55:18 Completed successfully
13:55:18
13:55:18 Done. PASS=5 WARN=0 ERROR=0 SKIP=0 TOTAL=5
We can confirm if the tables are available in BigQuery. On checking BigQuery console we could see that all the 5 tables are created as expected.
Our testing of the dbt model is successful from our local system. Let us now create a Dockferfile to create a container that would be executed from a Cloud Run Job.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
FROM python:3.8-slim
ARG PKG
WORKDIR /app
COPY ${PKG} /app
RUN pip install -r requirements.txt
RUN chmod +x ./script.sh
ENTRYPOINT ["./script.sh"]
We also create a file called script.sh which holds the command to run the dbt job. The reason to use a file, and then execute the file is that once we get the basic code working, we can expand in the future to perform multiple tasks like dbt seed, dbt test, etc.
1
2
#!/bin/sh
dbt run --project-dir dbt --profiles-dir dbt --target ${DBT_TARGET}
With this, we have come to the end of this part. We have successfully created a dbt job and can run it locally. We also created the Dockerfile needed to containerize the dbt job.
In the next part, let us explore about terraform to manage the infrastructure needed.