Automating Cloud Functions with GCS: A Terraform and GitHub Actions Guide

In a previous article, we saw how to set up Terraform on our local system and manage the resources in GCP. In this article, let us take it one step further and add GitHub Action to the mix.
Let us create a Cloud Function that gets triggered when a file is placed in a GCS bucket. The Cloud Function would read the contents of the CSV file and publish the row as a PubSub message.
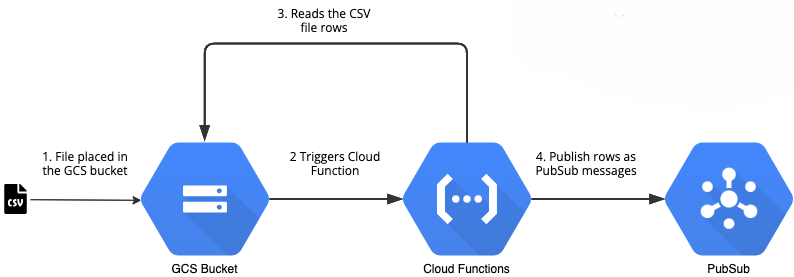
GCP Prerequisites
To manage Terraform, we need to perform the below tasks manually using the GCP Console.
Service Account for Terraform
We need to have a separate service account for Terraform to use when managing the GCP resources. This service account needs access to create and delete the services needed. We create a service account key and download it which we will maintain as a GitHub secret in our next step.
GCS Bucket for terraform state
When we ran Terraform from our local, you might have noticed a file called default.tfstate, which Terraform uses to know what it created earlier. Since we are going to run Terraform from GitHub Actions, we need to have a place for Terraform to write this state file and also pick the same file when the job runs again.
We created a GCS bucket for this purpose. Let us name it “terraform-state-files.” We can create a single GCS bucket and store the Terraform state file for all the modules in our project.
Manage GitHub secrets
When we ran Terraform from our local, we had our keys.json file on our file system. Since we cannot keep the credentials stored in a GitHub repository, we maintain them as GitHub secrets.
Create a new GitHub repository for our code base, go to “Settings,” and click on “Secrets and Variables” under “Security,” and choose “Actions.”
Here, click on “New repository secret” and the secrets that we would need. For our use case, we maintain the GCP Project ID, the region, and GCP_SA_KEY, and you just copy the entire contents of the keys.json file.

In fact, using the service account keys is not a preferred method, as this poses a security risk. Long-lived service account keys can pose a security risk if they are not managed correctly. The best way to avoid using service account keys in GCP is to use Workflow identity federation. We will try to cover this in a separate article in the future.
Project Structure
For our GitHub repository, let us use the following structure;
Our Cloud Function code goes inside the src folder. The Terraform code needed for our module goes inside the infra folder. And the GitHub Actions code goes inside the .github/workflows folder. Let us look at each part in detail.
1
2
3
4
├── .github
│ └── workflows
├── infra
└── src
Create Cloud Functions Code
We will create the code for the Cloud Function. The code would just read the CSV file from the GCS bucket, convert it into a Pandas data frame, and publish each row as a PubSub message.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import functions_framework
import os
from google.cloud import pubsub_v1
import json
import pandas as pd
import gcsfs
# Triggered by a change in a storage bucket
@functions_framework.cloud_event
def gcs_to_pubsub(cloud_event):
data = cloud_event.data
bucket = data["bucket"]
name = data["name"]
fs = gcsfs.GCSFileSystem(project=os.environ.get('PROJECT_ID'))
with fs.open(f'{bucket}/{name}') as f:
df = pd.read_csv(f)
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(os.environ.get('PROJECT_ID'),
os.environ.get('TOPIC_NAME'))
for row_index, row in df.iterrows():
message = json.dumps(row.to_dict()).encode('utf-8')
future = publisher.publish(topic_path, data=message)
print(future.result())
print("Completed")
Create Terraform Code
Let us now create the Terraform code to create the GCP resources needed.
First, let us create provider.tf, which holds the Terraform provider information.
1
2
3
4
5
6
7
8
9
10
11
12
13
terraform {
required_providers {
google = {
source = "hashicorp/google"
version = "5.21.0"
}
}
}
provider "google" {
project = var.project_id
region = var.region
}
function.tf holds the code needed for the Cloud Function
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
resource "google_cloudfunctions2_function" "function" {
name = "gcs-to-pubsub-function"
location = var.region
description = "A function triggered by GCS to publish to Pub/Sub"
build_config {
runtime = "python312"
entry_point = "gcs_to_pubsub"
environment_variables = {
PROJECT_ID = var.project_id,
TOPIC_NAME = google_pubsub_topic.topic.name
}
source {
storage_source {
bucket = google_storage_bucket.gcs-bucket-function.name
object = google_storage_bucket_object.function_code.name
}
}
}
service_config {
max_instance_count = 3
min_instance_count = 0
available_memory = "256M"
timeout_seconds = 60
environment_variables = {
PROJECT_ID = var.project_id,
TOPIC_NAME = google_pubsub_topic.topic.name
}
ingress_settings = "ALLOW_INTERNAL_ONLY"
all_traffic_on_latest_revision = true
service_account_email = google_service_account.service_account.email
}
event_trigger {
event_type = "google.cloud.storage.object.v1.finalized"
retry_policy = "RETRY_POLICY_RETRY"
service_account_email = google_service_account.service_account.email
event_filters {
attribute = "bucket"
value = google_storage_bucket.gcs-bucket-trigger.name
}
}
depends_on = [google_service_account.service_account,
google_project_iam_member.member-role]
}
We create 2 GCS buckets, one to store the Cloud Functions code and the other to trigger the Cloud Function when a file is placed in it. We also create a bucket object that copies the function code from a zip file onto the GCS bucket.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
resource "google_storage_bucket" "gcs-bucket-function" {
name = "module-a-cloud-functions-code-bucket"
location = var.region
}
resource "google_storage_bucket" "gcs-bucket-trigger" {
name = "cloud-functions-trigger-bucket"
location = var.region
}
resource "google_storage_bucket_object" "function_code" {
name = "function.zip"
bucket = google_storage_bucket.gcs-bucket-function.name
source = data.archive_file.function_code.output_path
}
We create the zip file for the Cloud Functions using the data.tf file. This would copy the contents into the src folder, create a zip file, and place it in the root folder.
1
2
3
4
5
data "archive_file" "function_code" {
type = "zip"
source_dir = "${path.root}/../src"
output_path = "${path.root}/function.zip"
}
We create the service account that the Cloud Function uses and provide the necessary roles needed for it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
resource "google_service_account" "service_account" {
project = var.project_id
account_id = "cloud-function-worker"
display_name = "Cloud Function Service Account"
}
resource "google_project_iam_member" "member-role" {
for_each = toset([
"roles/eventarc.eventReceiver",
"roles/run.invoker",
"roles/pubsub.publisher",
"roles/storage.objectUser",
])
role = each.key
member = "serviceAccount:${google_service_account.service_account.email}"
project = var.project_id
}
We create a PubSub topic that the Cloud Function publishes messages to.
1
2
3
4
resource "google_pubsub_topic" "topic" {
name = "cloud_function_trigger_topic"
project = var.project_id
}
As we explained earlier, we need to maintain the backend that Terraform should use to store the state files. We could use the same GCS bucket for storing the state file for multiple modules by changing the prefix. In our case, we used “moduleA” as an example name for this module.
1
2
3
4
5
6
terraform {
backend "gcs" {
bucket = "terrafom-state-files"
prefix = "moduleA/terraform/state"
}
}
We create the variables that are used in our project. The value for these would be passed through the GitHub Actions, which would be picked up from our secrets.
1
2
3
4
5
6
7
8
9
10
variable "project_id" {
description = "GCP Project ID"
type = string
}
variable "region" {
description = "GCP Project Region"
type = string
}
Create GitHub Actions Workflow.
After we have configured the code and the infrastructure needed for it, we pay attention to GitHub actions. We need to create a workflow from which we can perform terraform plan, terraform apply and terraform destroy.
Create a file called deploy_infra.yaml and have the below contents in it.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
name: Deploy to Google Cloud
on:
workflow_dispatch:
inputs:
terraform_operation:
description: "Terraform operation: plan, apply, destroy"
required: true
default: "plan"
type: choice
options:
- plan
- apply
- destroy
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3.0.0
- name: Build zip file
run: |
cd src
zip -r ../function_code.zip .
cd ..
- id: "auth"
name: "Authenticate to Google Cloud"
uses: "google-github-actions/auth@v1"
with:
credentials_json: "$"
create_credentials_file: true
export_environment_variables: true
- name: Setup Terraform
uses: hashicorp/setup-terraform@v1
- name: Terraform init
run : |
cd infra
terraform init
- name : Terraform Plan
env:
TF_VAR_project_id: $
TF_VAR_region: $
run: |
cd infra
terraform plan
if: "$"
- name: Terraform apply
env:
TF_VAR_project_id: $
TF_VAR_region: $
run: |
cd infra
terraform apply --auto-approve
if: "$"
- name: Terraform destroy
env:
TF_VAR_project_id: $
TF_VAR_region: $
run: |
cd infra
terraform destroy --auto-approve
if: "$"
Running the GitHub Actions
Once we push all the changes to GitHub, when we go to the “Actions” tab, we see our new action, “Deploy to Google Cloud.”
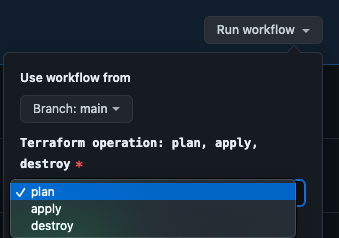
This would give us three options for what we could choose. We can choose ‘plan’ to see what Terraform would create or ‘apply’ to create the resources.
We choose ‘apply’ and click ‘Run workflow’.
We could see that all the steps were completed for our workflow. 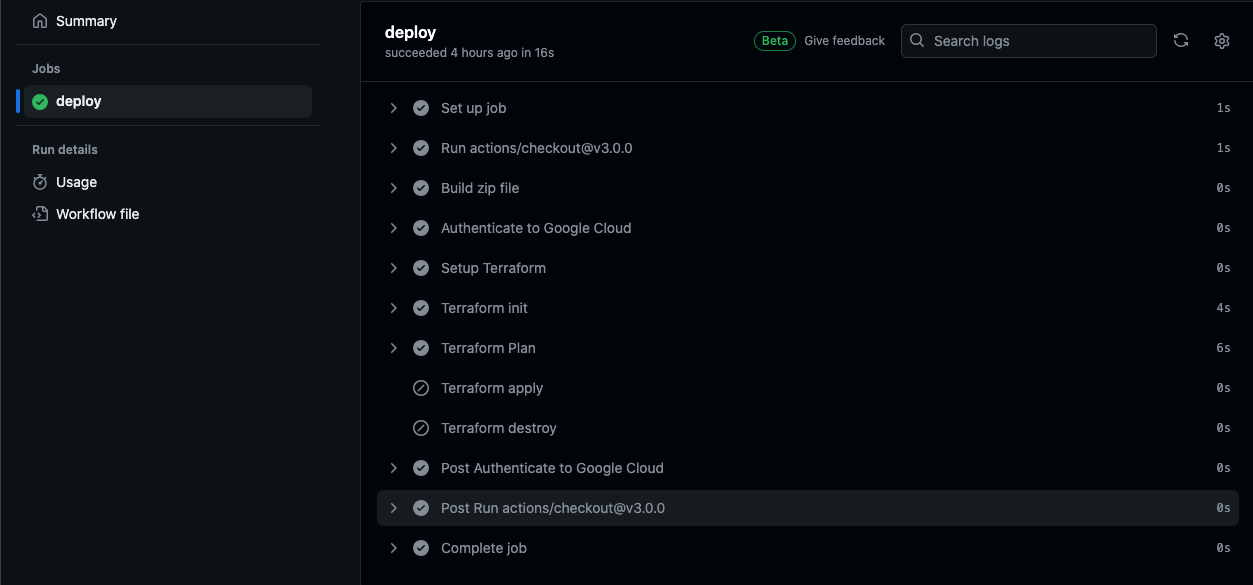
We can check in GCP if the Cloud Functions, PubSub topic, and GCS buckets are created.
Cloud Functions 
PubSub 
GCS Bucket 
Testing the Cloud Function
Now that we have all the services deployed, let us place a CSV file inside the GCS bucket and see if everything works. We also need to create a subscription for the PubSub topic, which we didn’t create it earlier from Terraform.
Placing a sample file, customer-100.csv, in the GCS bucket 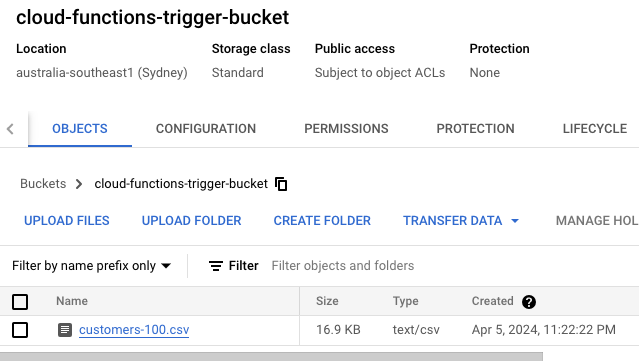
We could see that the Cloud Function got triggered after we placed the GCS file. The log message shows the PubSub message IDs that were published and ends with the “Completed” message. 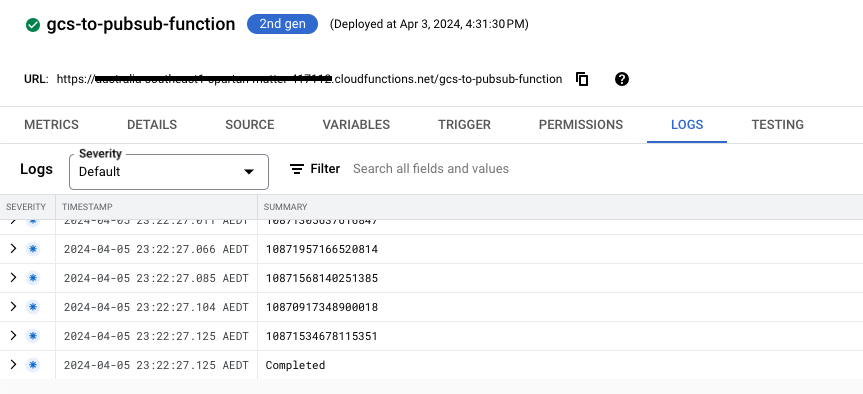
Let us now check the PubSub subscription and see if any messages were received.
We could see the PubSub messages in the subscription. 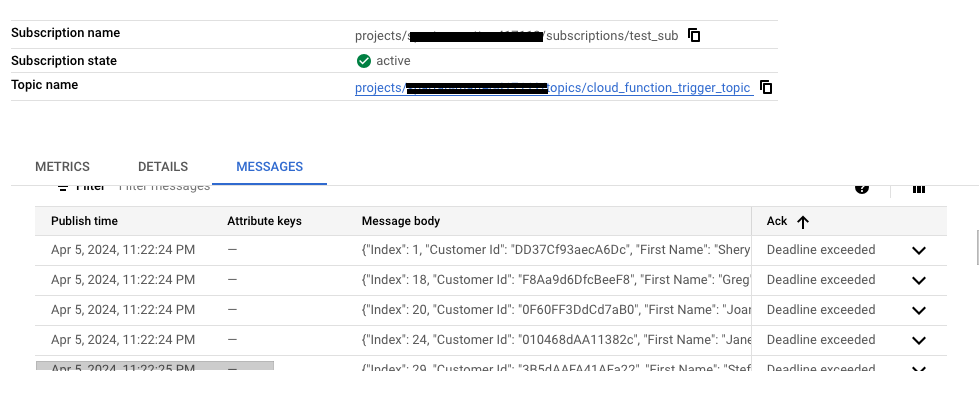
We have covered a lot of things in this article. We started with a Cloud Function that gets triggered when a file is placed in a GCS bucket and publishes the rows as PubSub messages, then we added the Terraform code needed for this, and finally, we included GitHub Actions to perform the CI/CD needed.
Currently, the GitHub action is manually triggered. We could easily change the code to do all this whenever a pull request is merged to the main branch, add in unit testing for the Cloud Function code, add a SonarQube test, add Checkmarx, etc. All these additional GitHub Actions could be dependent on the project and the company with which you work. But you get the idea.